一致性哈希
最近我碰到过几次使用一致性哈希的情况。介绍这个概念的论文《一致性哈希和随机树:分布式缓存协议,用于解决互联网应用中的热点问题。David Karger等人著》 出现在十年前,不过最近似乎这个概念已经悄悄地应用到从亚马逊的"Dynamo"到Last.fm提供的"Memcached"等越来越多的服务当中。那么,什么是一致性哈希,为什么要关心它?
源文: Consistent Hashing (Tom White)
对一致性哈希的需求来自于多个缓存服务器缓存对象一些限制--例如,Web缓存。想象这样的场景,在使用n台缓存服务器(编号1到n)时, 一种常用的负载均衡方式是,对资源对象o的请求使用hash(o)先取哈希值,然后对n取模(mod n), 这样得到的值(hash(o) mod n)就是对应缓存服务器的编号,该缓存就会放在对应编号的缓存服务器上。 这工作良好,直到你添加或删除缓存服务器(无论出于什么原因),因为此时n发生了变化,每个对象都会被哈希到一个新的位置。这可能是灾难性的,这会使得缓存服务器大量集中地向原始内容服务器更新缓存,从而造成服务器的瘫痪。 这就好像缓存突然消失了一样。从某种意义上来说,它已经消失了。这就是为什么你应该关心一致性哈希的原因:需要一致哈希算法来避免这样的问题!
如果添加一台缓存服务器时,它应该能从所有其他缓存服务器中获取它应得的对象;同样,当移除一台时,它的对象应该能被其余的服务器共享。 这正是一致性哈希所做的事情--将对象一致地映射到同一台缓存服务器上,至少在可能的情况下,是这样的。
一致性哈希算法背后的基本思想是使用相同的哈希函数对对象和缓存进行哈希。这样做的原因是将缓存映射到一个区间,这个区间将包含一些对象哈希。如果缓存被移除,那么它的区间就会被一个具有相邻区间的缓存接管。所有其他缓存保持不变。
证明
我们来详细看看这个问题。哈希函数实际上是将对象和缓存映射到一个数字范围。这应该是每个Java程序员都熟悉的: Object上的hashCode方法返回一个整数,它位于-2 31到2 31-1的范围内。 想象一下,把这个范围的数值环绕起来,就映射成了一个圆。下面是一张圆的图片,在它们哈希到的点上标记了一些对象(1、2、3、4)和缓存(A、B、C)(基于David Karger等人的《具有一致哈希的Web缓存》中的一张图)。
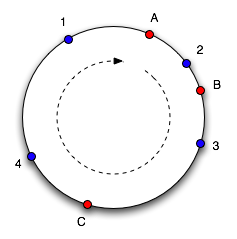
为了找到一个对象的缓存位置,我们顺时针绕着圆移动,直到找到一个缓存点。所以在上图中,我们看到对象1和4属于缓存A,对象2属于缓存B,而对象3属于缓存C。 考虑一下如果缓存C被删除会发生什么:对象3现在属于缓存A,而所有其他对象的映射没有变化。如果再在标记的位置增加一个缓存D,它将带走对象3和4,只留下属于A的对象1。
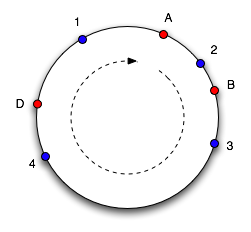
这样做的效果很好,只是分配给每个缓存的间隔大小很不理想。由于本质上是随机的,所以有可能在缓存之间的对象分布非常不均匀。 解决这个问题的方法是引入 "虚拟节点 "的概念,虚拟节点是圆内缓存点的复制。所以每当我们添加一个缓存时,我们就会为它在圆中创建一些点。
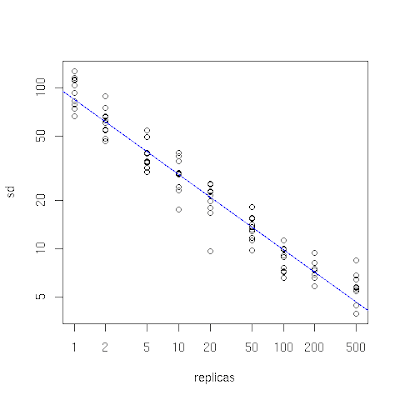
你可以在下面的图中看到这个效果,这是我用下面描述的代码模拟在10个缓存中存储10000个对象而制作的。 在x轴上是缓存点的复制数(虚拟节点)(用对数刻度)。当它很小的时候,我们看到对象在各缓存中的分布是不平衡的,因为标准差作为每个缓存的平均对象数的百分比(在y轴上,也是对数)很高。 随着复制数(虚拟节点)的增加,对象的分布变得更加平衡。这个实验表明,一两百个副本(虚拟节点)的数字可以达到一个可接受的平衡(标准偏差大致在平均值的5%到10%之间)。
实现
这里是一个简单的Java实现。为了使一致性哈希有效,拥有一个能很好散列的哈希函数是很重要的。 Object的hashCode的大多数实现都不能很好地散列--例如,它们通常会产生数量有限的小整数值--所以我们有一个HashFunction接口来允许使用自定义的哈希函数。这里推荐使用MD5哈希。
1import java.util.Collection;
2import java.util.SortedMap;
3import java.util.TreeMap;
4
5public class ConsistentHash<T> {
6
7 private final HashFunction hashFunction;
8 private final int numberOfReplicas;
9 private final SortedMap<Integer, T> circle =
10 new TreeMap<Integer, T>();
11
12 public ConsistentHash(HashFunction hashFunction,
13 int numberOfReplicas, Collection<T> nodes) {
14
15 this.hashFunction = hashFunction;
16 this.numberOfReplicas = numberOfReplicas;
17
18 for (T node : nodes) {
19 add(node);
20 }
21 }
22
23 public void add(T node) {
24 for (int i = 0; i < numberOfReplicas; i++) {
25 circle.put(hashFunction.hash(node.toString() + i),
26 node);
27 }
28 }
29
30 public void remove(T node) {
31 for (int i = 0; i < numberOfReplicas; i++) {
32 circle.remove(hashFunction.hash(node.toString() + i));
33 }
34 }
35
36 public T get(Object key) {
37 if (circle.isEmpty()) {
38 return null;
39 }
40 int hash = hashFunction.hash(key);
41 if (!circle.containsKey(hash)) {
42 SortedMap<Integer, T> tailMap =
43 circle.tailMap(hash);
44 hash = tailMap.isEmpty() ?
45 circle.firstKey() : tailMap.firstKey();
46 }
47 return circle.get(hash);
48 }
49
50}
哈希圆用排序的整形映射来表示,整数代表映射到缓存的哈希值(这里是T类型)。 当一个ConsistentHash对象被创建后,每个节点都会被添加到圆中若干次(由numberOfReplicas控制)。每个副本(虚拟节点)的位置是通过对节点的名称和数字后缀进行哈希来选择的,节点被存储在图中的这些点上。
要找到一个对象的节点(get方法),就要用对象的哈希值在圆中寻找。大多数情况下,在这个哈希值处不会存储有节点(因为哈希值空间通常比节点数量大得多,即使是复制点也是如此), 所以通过在映射末尾寻找第一个键来找到下一个节点。如果映射末尾是空的,那么我们就通过获取圆的第一个键。
使用
那么如何使用一致性哈希算法呢? 使用现成的库,而不是要自己编码。比如上面提到的Memcached,一个分布式内存对象缓存系统,现在已经有支持一致性哈希的客户端。 如最初的ketama哈希算法,作者是Last.fm公司的Richard Jones;现在还有Dustin Sallings的Java实现(这启发了我上面的简化演示实现)。 有趣的是,只有客户端需要实现一致性哈希算法--Memcached服务器是不需要的。其他采用一致性哈希的系统包括Chord,它是一个分布式哈希表的实现,以及Amazon的Dynamo,它是一个键值存储(在Amazon之外无法使用)。
(全文完)